How to DESTROY your AWS services, a Platform journey Vol.1
Table of Contents
This is a series of articles about AWS automation with terraform. In this volume we will discuss the overall architecture we want to accomplish as well as some easy exercises with chaos engineering to test real world edge cases.
This chaos experiments will help us to understand the goodies and the limitations of our infrastructure.
First things first.
As a developer I want to have a solid pipeline where I only need to be worry about code and tests. After I commit my changes into a repository I get all the feedback about my code analysis and tests in a production like environment. If I did my work well the promotion to production, for instance, should be automatic (or validated by other developer).
Discussing the pipeline is out of scope for this series of articles but I plan to have an entire set of articles about CI/CD. Just bare with me.
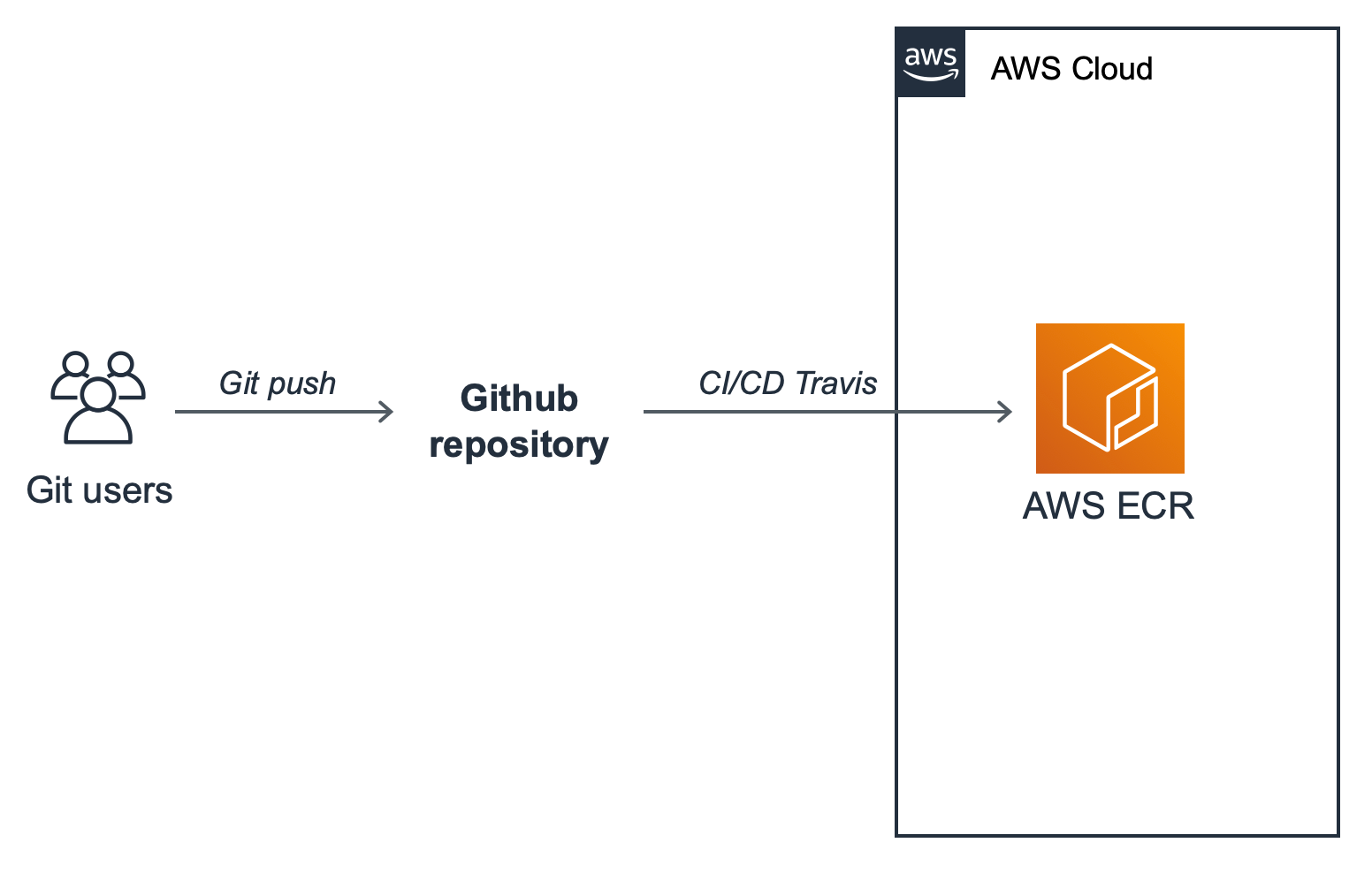
In this scenario let's assume we want to work with Docker. Next up is getting our Docker image up into AWS's EC2 Container Registry (ECR). While we could use Docker Hub, ECR comes with all of the usual benefits of using other AWS services with other AWS services.
Any time a new feature is committed to the master branch the pipeline will trigger the update and retag the latest version in ECR.
Following with the architecture let's take a loot at the diagram.
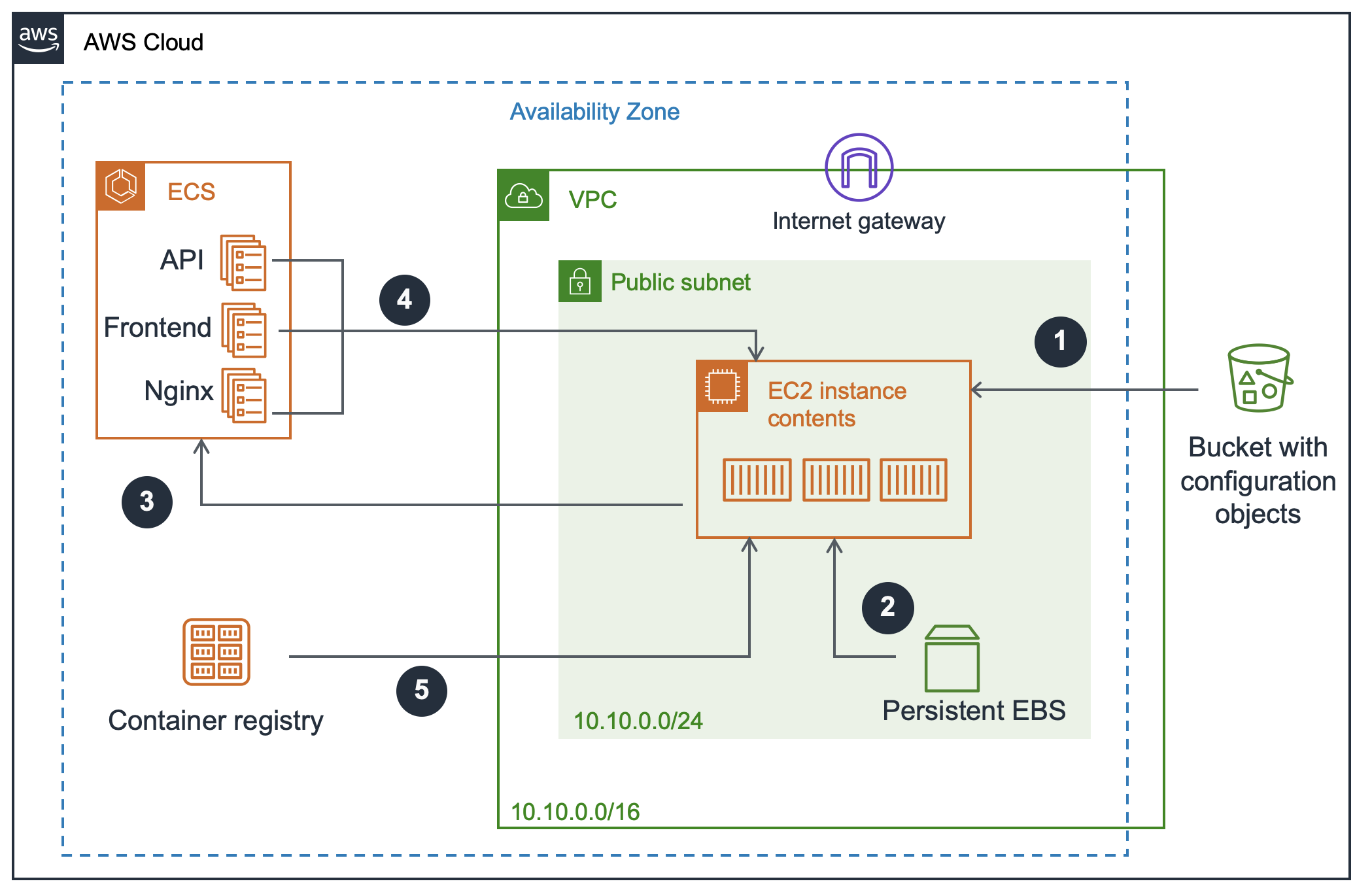
The main core of the platform will be the ECS cluster.
An Amazon ECS cluster is a regional grouping of one or more container instances on which you can run task requests. It help us to deploy and handle the Docker images from the different services.
Even thought you can have multiple EC2 instances linked to a single ECS cluster, in this case we will only use one (money constrains).
The EC2 instance will hold three containers, this containers are described in the task definitions of the ECS (the technical details will be covered in Volume 2). We are going to deploy 3 services, a frontend, an API (Golang) and a reverse proxy (Nginx). The reverse proxy will download, renew open certificate authorities and handle the traffic.
This overall view of the architecture and services is enough to start questioning some scenarios. As lazy developers we always need to thing about automation, otherwise you will be loosing time, money and let's be real it is not fun at all. After all in the process of automation you end up learning new technologies and techniques.
The CHAOS
Let's do some CHAOS
In a nutshell Chaos engineering is experimenting on a software system in production in order to build confidence in the system's capability. It allows you to ask questions you won't necessarily think about while developing.
To replicate the following experiments you might want to install the following dependencies.
$ pip install -U chaostoolkit chaostoolkit-reporting
$ brew install awscliStarting with the assumption the instance is healthy. We can test the behaviour of the services.
In the first scenario we are going to simulate a random shutdown of one of the services. Poor implementation of the API, heavy requests, raising the service's memory or CPU limit... could be real-world triggers. Terminating the API service should not prevent the rest of the applications from running. Our architecture does not have any dependency with the API, we assume the frontend is a 3rd party service with no integration with the API.
Every service terminated should come back to life from our ECS cluster. Meaning the impact for the clients using our API should be minimal. As we are going to see in the next volumes of this series, we could specify multiple services of the same image. While one service could face a shutdown the rest services should be able to handle the requests properly and assure the availability of the resource.
Spoiler alert: Have a look at the reverse-proxy
For the sake of simplicity we are going to use mainly the process provider and run awscli and ssh scripts. Interpolation might be tricky for chaostoolkit, for that reason we call an external bash script.
#!/bin/bash
aws ecs \
describe-services \
--services api blog nginx \
--cluster $CLUSTER \
--query 'length(services[?status==`ACTIVE`])'#!/bin/bash
ssh $USER@$SERVER \
docker stop \
$(ssh $USER@$SERVER docker ps -q --filter 'name=ecs-api-*' --format='{{.ID}}')All this experiments, as well as the final report is available in this repository. New scenarios might be included.
A dive into the report
If the reverse-proxy is terminated our services won't be reachable from internet although that doesn't prevent applications from running.
While the reverse-proxy is up and running, a shutdown of any service won't prevent applications from running neither block any request from the internet.
If you had a look at the experiments you probably noticed the emptiness of the rollbacks section. ECS can handle the shutdown of our services pretty fast triggering the start of a new container.
Now that we understood the limits of the platform we can have a look at the implementation as code with terraform. Follow the next article of this series by searching for the platform-journey tag.
Resources
- https://github.com/dastergon/awesome-chaos-engineering
- https://www.oreilly.com/ideas/chaos-engineering
- https://principlesofchaos.org/?lang=ENcontent
CHANGELOG
- 2019 September 18 - ADD Resources